Space Data Centers Will Be Much Smaller Than Their Terrestrial Counterparts

Introduction
Massive public pushback in the US against AI data center buildout is giving more validity to the notion that despite massive hurdles to overcome, reduced regulatory friction may drive a large amount of AI compute deployment in orbit. However, you can’t hire a few thousand local workers, rent construction equipment, and start trucking in your GPUs to space like you can on Earth. This brings into question how the construction, maintenance, and economics of space data centers will drive different architectural decisions, especially with the current deployment options available this decade. Starcloud’s 2024 whitepaper outlines GW scale datacenters as massive single structures. On the opposite end of the spectrum, SpaceX just filed a request with the FCC to launch one million satellites to form their orbital data centers. As I explain below, I think the satellite constellation architecture is much more likely to succeed, especially in the early days.
Design, Build, Test Loop
Design, build, test. Space is a demanding environment, and success is best found by finding all the ways to fail – as fast as possible. This test early & often, battle-hardening approach has been popularized in the modern era by SpaceX, but it was used in the 20th century American aerospace industry as early as Project Gemini. But this fail fast approach only works if your design, build, test loop is rapidly executed at a reasonable price. Optimizing for ability to iterate drives different decisions at the architectural level to ensure your product is on the ‘Iterability Flywheel.’
Iterability Flywheel
The iterability flywheel goes like this: simplify your product -> your product can be made faster & cheaper-> test more & get your product to market -> use learnings from test and earnings from sales to simplify & improve your product.
Things get easier and cheaper to make when the product you are manufacturing is simpler. When things are easier and cheaper to make, you can make more of them. And you can test more. And you can cut in iterations more easily. Design, build, test loop runs on steroids with a product that can be quickly built, easily iterated on without massive CAPEX investment/waste, and is cheap to make at a high quantity. For the same cost, you can get 10 iterations of a $100 product versus 1 iteration of a $1,000 product. You also get good at rate manufacturing, which almost every product needs to figure out eventually to unlock the benefits of economies of scale. The factory is the product etc.
An often-undiscussed benefit of this flywheel is faster path to revenue. When your system is simpler and smaller, you can manufacture and deploy faster, and a single unit generates revenue instead of waiting for "one huge thing" to be complete. In addition to feeding your company's growth, you get the added benefit of learning what your customer actually wants. Solar vs nuclear is a classic example. A solar farm starts generating revenue with the first panel connected to the grid, while a nuclear plant doesn't make a penny until the entire facility is finished and licensed.
When a large-scale engineering project is started, the “system” is typically broken down into smaller subsystems and components within the subsystems. As the system scales in size and complexity, so do the subsystems and so does the organization attempting to make it. This comes with a litany of challenges ranging from increased difficulty and cost in testing at the system-level to higher administrative cost to increased complexity in communication between teams. But, as stated, these are “large-scale” engineering projects, so how do you achieve your goal without a large system? The key distinction lies in building a single monolithic structure vs deploying a high volume of smaller identical products to achieve the same goal.
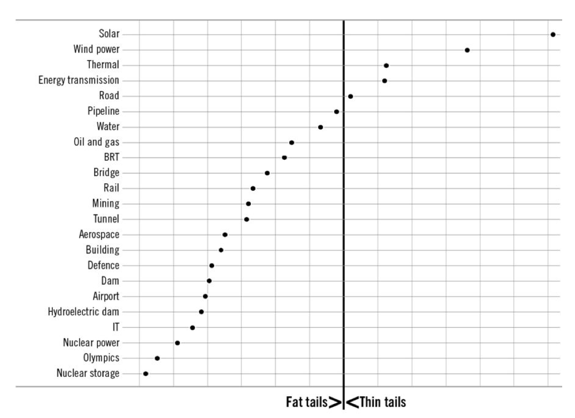
Bent Flyvbjerg and co-author Dan Gardner came to this conclusion in the book How Big Things Get Done (paper Flyvbjerg wrote on the topic here) after studying thousands of megaprojects across industries. Flyvbjerg found many examples where modularity (many of one thing) beats “one huge thing” as he calls it (solar, wind, satellite constellations). The nuclear industry seems to have learned this, as almost all startups are now pursuing SMRs (small modular reactors) as opposed to the giant nuclear plants of past eras. The graph below from Flyvbjerg’s book shows categories of megaprojects in terms of likelihood to run over schedule and over budget (left) to those likely to complete on time and on budget (right). The worst “fat-tail” offenders are all “one big thing” projects.
Application to Space Data Centers
On Earth, data centers somewhat follow the modular architecture already. GPU clusters are modular in the sense that you are networking together tons of GPUs, and the buildings around them are well-understood technology (large warehouses, cooling, generators, fiber). In space, the structure to store all of those GPUs is not a given. There is no empty warehouse in space. This is why I would argue that space data centers are going to manifest as satellite constellations instead of giant orbital megastructures. The question is not which system is "right” in the long term, but which one gets you to a working, revenue-generating product faster, and which one absorbs the inevitable lessons about operating GPUs in orbit at the lowest cost.
Manufacturability is a huge factor here. A Starlink-sized satellite is a product you can build on a line. With a product made at a higher rate, you are not only experimenting with the product itself, you’re experimenting with the way you make the product. You can buy more parts off the shelf AND you can buy more tools off the shelf. Finding out that you bought the wrong used shipping container is a somewhat cheap lesson to learn. Compare that to a multi-hundred-ton orbital structure, where every piece of ground support equipment (every fixture, every transport rig, every clean-room enclosure) is itself a one-off engineering project. Imagine you're the program manager and your team designs and fabricates a perfect custom shipping fixture for the structure's central truss. Great. Now the satellite team wants to iterate on the truss geometry. Do you constrain the redesign to fit the original fixture? Do you pay for a new custom fixture? Do you keep a full-time engineer on staff just to track which revision goes with which ground support hardware? Every dimension you change on the megastructure side ripples through a multi-layered custom supply chain.
Assembly is another key consideration. A constellation does not need to be physically assembled in orbit. Each satellite is its own complete, self-contained unit, and the "assembly" consists of the satellites taking up their assigned positions and ensuring communication with ground stations and/or other satellites. A megastructure is the opposite. Assuming it takes more than one Starship or New Glenn launch to deliver a completed monolithic datacenter to orbit, you need to physically connect modules together in vacuum, route power and thermal between them, and verify successful connections. The ISS took 13 years and more than 30 assembly flights to build, and that was with a fleet of crewed shuttles, EVA-trained astronauts, and multi-decade international program funding. We don't yet have a commercial track record for autonomous orbital assembly at the scale a megawatt-class compute structure would require, and the development of that capability is itself a multi-billion-dollar, multi-year side quest that the constellation approach does not have to take.
System-level fault tolerance is another massive benefit of a distributed architecture. The same way a scrapped unit on the assembly line does not tank the program, a failed satellite on orbit does not tank the entire program in a constellation. In a distributed system, a single failure is a rounding error. Starlink already operates this way. SpaceX has initiated controlled deorbits on >100 satellites over the life of the constellation, including a proactive 2024 campaign to bring down ~100 early V1 satellites after engineers found a common-mode issue that could increase failure probability over time. The company explicitly stated the deorbits would not impact broadband service. Compare this to a megastructure, where a serious anomaly in a central system (the main truss, the primary radiator network, the central power bus) potentially takes a meaningful fraction of your compute capacity offline at once. You can engineer redundancy into a monolith, but the cost and complexity of doing so scales with the structure itself. Constellations, on the other hand, not only have inherent robustness from lack of single-point-failures but also gain robustness from the (always increasing) piles of real-world data they collect as they deploy more satellites.
Counterpoint: The Latency Problem
All of this sounds great until you ask yourself why data centers on the ground are so large in the first place. For example, Meta's Hyperion campus under construction in Louisiana is about one sixth the size of Manhattan. Acquiring land, single-point grid connections, shared cooling and water infrastructure are not necessarily problems for a space data center constellation. But there is one big problem that is: networking GPUs as physically close to each other as possible. To understand whether that requirement is going to buy its way on to space-based data centers, we have to look at the two main categories of AI compute: training and inference.
Modern frontier model training does not consist of GPUs working independently and reporting back at the end. It is tens of thousands of GPUs locked in tight, synchronous lockstep, exchanging gradient updates hundreds of times per training step. This is why on-the-ground clusters obsess over interconnect bandwidth. Top-tier training systems use InfiniBand or specialized Ethernet between nodes (~400 Gb/s) all within the same building. For comparison, Starlink's optical inter-satellite links run somewhere around 100 Gb/s per link. That is impressive for laser communication across thousands of miles of vacuum, but it is roughly 25% of what a co-located GPU fabric delivers. And that is before accounting for the multiple satellite-to-satellite hops you would need to reach all the nodes in a constellation-scale training run. The math gets ugly fast. Gradient synchronization gates every step, so a 4x interconnect penalty stretches a three-month training run into a year-long one.
Fortunately for the constellation architecture, AI inference usage is a large and growing chunk of data center compute. McKinsey predicts that more than half of data center compute will be inference by 2030. Inference jobs are loosely coupled and tolerant of much higher latency. They do not need every GPU to talk to every other GPU thousands of times per second. Your ChatGPT conversation can be completed between your phone and a satellite passing overhead. Longer conversations may require transfers between satellites as they orbit Earth, but this is a problem that should be solvable with dedicated engineering. This is why the latency problem, while real, does not kill the constellation architecture. It just narrows the use case to inference for the near term. Training in space is a problem to solve later, possibly with a different architecture.
Conclusion
The megastructure vision is not necessarily wrong as an end state. It is just a hard place to start. As much as system architects do not want it to be true, the form factor of products is heavily shaped by environmental conditions that allow it to exist. The recurrent laryngeal nerve in a giraffe runs from the brain down the neck, loops around the aorta, and runs back up to the larynx. It is a 15-foot detour for a connection that should be a few inches, because that is how the wiring was inherited from a fish-shaped ancestor where the same path was efficient. Starting conditions have a long half-life.
Tools and machines starting small and growing over a large period of time is a pattern in humanity’s history of invention. Blast furnaces started small and got bigger over decades as demand for steel increased and steelmakers began to take advantage of the square-cube law in their furnace sizing. Rockets are doing it now (Falcon 1 -> Falcon 9 -> Starship, New Shepard -> New Glenn). The constellation-first approach is a product of where the industry is right now: early, capital constrained, unsure of what the customer actually wants, and without humans in orbit to fix anything that breaks. The constellation architecture is the form that survives those constraints. Starcloud's roadmap is a useful tell. Their 2024 whitepaper described a single gigawatt-scale structure; their website now lists Starcloud-1, 2, 3, and 4 which outline a multi-stage evolution from small sat to constellation to megastructure.
If the theoretically ideal space data center is a giant monolithic structure (denser internal GPU fabric for training, better surface area to volume ratio for shielding), it comes later. The cool thing is that assembly of these megastructure datacenters may be the economic engine that drives humans living and working in orbit. But the path to the megastructure likely runs through the deployment and learnings from constellations. Revenue from inference satellites funds larger structures, which justify the assembly capacity, which justifies the human presence.